Linear Regression Model
In a simple linear regression problem, our goal is to fit a straight line to data points 


The model is expressed as:
— the weight (slope of the line)
— the bias (intercept)
— the predicted value of
The objective of linear regression is to find parameters
Squared Error Cost Function
To measure how well our model fits the data, we use the Mean Squared Error (MSE) cost function:

Substituting 

Here, 
Gradient Descent Algorithm
Gradient Descent is an iterative optimization algorithm that finds the parameters $(w,b)$ minimizing 
$latex
\begin{aligned}
w &:= w – \alpha \frac{\partial J(w,b)}{\partial w} \\
b &:= b – \alpha \frac{\partial J(w,b)}{\partial b}
\end{aligned}
$
where 
Gradient Derivations
To implement gradient descent, we need the partial derivatives of
Partial Derivative with Respect to
Start with:

Differentiate with respect to

Partial Derivative with Respect to
Similarly, differentiating with respect to

Gradient Descent Update Rules
Substituting the gradients into the update equations gives:
$latex
\begin{aligned}
w &:= w – \alpha \frac{1}{m} \sum_{i=1}^{m} ( wx^{(i)} + b – y^{(i)} ) x^{(i)} \\
b &:= b – \alpha \frac{1}{m} \sum_{i=1}^{m} ( wx^{(i)} + b – y^{(i)} )
\end{aligned}
$
These equations iteratively adjust
Understanding Gradient Descent Behavior
To build intuition for gradient descent, consider the cost surface
For linear regression,
Each point on this surface corresponds to a different pair of parameters 
Gradient descent starts at some initial guess 
In general machine learning problems, gradient descent can sometimes converge to a local minimum instead of a global minimum.
However, for linear regression, the cost function:
is a convex function.
This means it has a single global minimum and no local minima — gradient descent will always converge to that global minimum if the learning rate
Convexity and Convergence
Definition of Convexity:

Intuitively, this means the line segment connecting any two points on the curve of 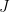
For convex functions, gradient descent is guaranteed to reach the global minimum if
- The cost function in linear regression is convex.
- Gradient descent always converges to the global minimum (no local minima).
- The choice of
Visualization (Conceptual)
Imagine the cost function surface as a smooth 3D bowl:
- The horizontal axes represent parameters
- The vertical axis represents the cost
- The global minimum is at the bottom of the bowl.
Gradient descent starts at some initial point and takes small steps downhill until it reaches the minimum.

Figure: Visualization of the convex cost function surface
Make a one-time donation
Make a monthly donation
Make a yearly donation
Choose an amount
Or enter a custom amount
Your contribution is appreciated.
Your contribution is appreciated.
Your contribution is appreciated.
DonateDonate monthlyDonate yearly
Leave a Reply